AI画像生成における学習 (その1)
AI画像生成における学習?
AI画像生成では、学習済みモデル(*1) という学習済みのデータを使って画像を生成します。膨大な量の画像データから学習を行った結果のモデルであるので何でも生成できそうなのですが、さすがに出力したい画像がモデルの中にない場合には残念ながら出力することができません。それなら、「無ければ作ればいい」の精神で自分で作ることができればいいのですが、残念ながら個人が買うようなPCでは納得のできるような画像生成用の学習済みモデルを作ることはできません。噂によるとあるモデルでは、作成するのに高級車が買えるような法人用のサーバーを複数台利用したうえで何週間もかかったとのこと。これは流石に個人レベルでは手を出すことが出来ません。
しかし、そんな中、LoRA( Low-Rank Adaptation の略、読みはロラあるいはローラ)という技術が生まれました。これを使うと学習済みモデルは作ることはできないのですが、学習済みモデルの作成に比べて「より少ない資源」で「既存の学習済みモデルに追加の学習」を行うことができるようになりました。これにより、個人が利用するようなGPUを利用して画像生成AIの追加学習も可能になりました。
学習できる環境としては整ってきたものの、LoRAの元となる学習済みモデル(以下 checkpoint と表記) は多彩にあり、それぞれ得意な画風や特徴のある絵柄などで同じプロンプトを入力しても全く違った絵が生成されるほどに違いがります。
CivitAI モデルダウンロードサイト 人気が有り過ぎて動作が重くなってしまうことも…
https://civitai.com/models
このためLoRA作成の為の追加学習を行うにしてもスタート地点から異なってくるという状況であり更にはその学習方法やパラメータなどが驚くほど多く「こうすれば誰でも上手くLoRAが作れる」という状況ではありません。
それでも自分好みの絵を作り出すモデルを作りたいという願望は強いのか、LoRA作成の為のツールがGitHubにアップされたりLoRA作成のためのノウハウが少しずつWebサイトに上がってくるようになり、私でもなんとかLoRAが作成できるようになりました。
早速作ってみることにしましょう。
1. 素材画像集め
まずは素材となる画像を集めます。とは言え何でもいいというわけには行きません。ましてはここは会社のBlogですから?
というわけで弊社のマスコットキャラクターであるセイル君に登場していただきました。

弊社のWebページから引っ張ってきました。元は JPEG 形式だったのですが、PNG形式にした上で、画像編集ツールでJPEG特有のザラザラしたノイズを除去してあります。SDXLモデルに対するLoRA作成に使用するため1024×1024 サイズにリサイズしています。どうやっても公式画像がこの1枚なので実用的ではありませんが、ここではそういったことは気にせず、セイル君を出しまくる(というかセイルくんしか出ない)LoRAを作ることにします。
AIにセイルくんを覚えてもらう為に必要なのは、画像と「キャプション」と呼ばれる画像が何を表しているのかをテキストで表したものです。
今回は sail_kun をこの画像のキャプションとしてつけ、sail_kun と プロンプトに書かれた場合にこの画像を出してもらうこととします。
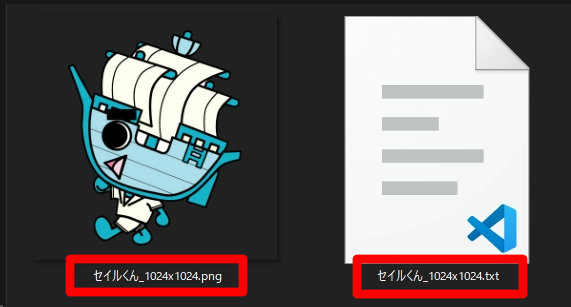
こんな感じで、セイルくんの画像と同じ名前で拡張子のみ txt としたファイル作成して、中に
sail_kun
とだけ記載して保存しておきます。
これを 160_sail_kun というフォルダに入れて更にそのフォルダを train というフォルダの中に置きます。
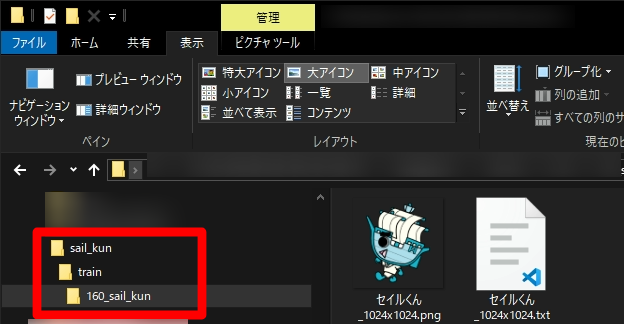
そしてこれを
kohya-ss / sd-scripts (https://github.com/kohya-ss/sd-scripts) と RedRayz / Kohya_lora_param_gui (https://github.com/RedRayz/Kohya_lora_param_gui)(両方とも作者が日本人なので解説も日本語付き! 日本人でよかった!)を組み合わせて利用してLoRAを作ります。
2. 学習パラメータの設定
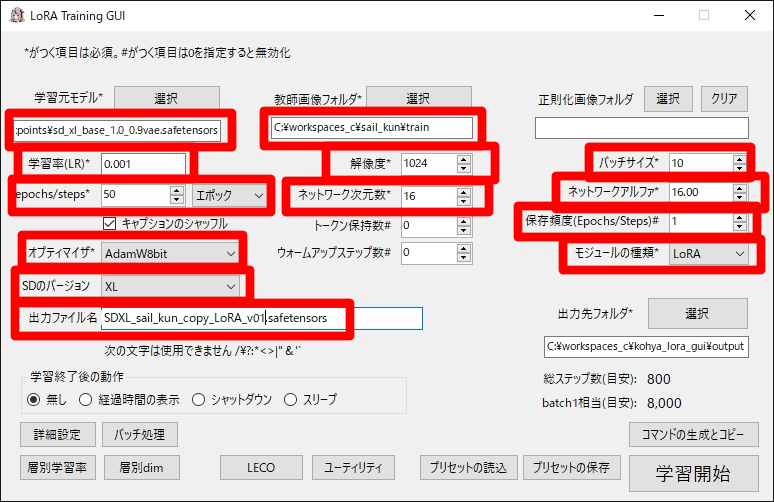
学習元モデル、学習率(Learning Rate, LR) 、epocks/steps、オプティマイザ、SDのバージョン(Stable Diffusionのバージョンのこと。 学習元モデルと同じバージョンする必要がある)、出力ファイル名(出来上がるLoRAのファイル名)、教師画像フォルダに先ほど作成したセイル君の入った train フォルダ、解像度(SD1.5なら512、SDXL は 1024が推奨値)、ネットワーク次元数、バッチサイズ(同時に学習する画像の数。VRAM使用量がオーバーしない程度に大きくすると効率が良い。1なら8GB程度でも可能。)、保存頻度(Epocks/Steps 規定epochs/steps に到達する前の途中経過のモデルを出力する。学習の状況を確認できる。) 、モジュールの種類(LoRA) を設定します。
更に詳細設定のページで、スケジューラ設定します。ここでは通常あまり使われない constant (ずっと同じLRを使用する)を意図的に選択しています。
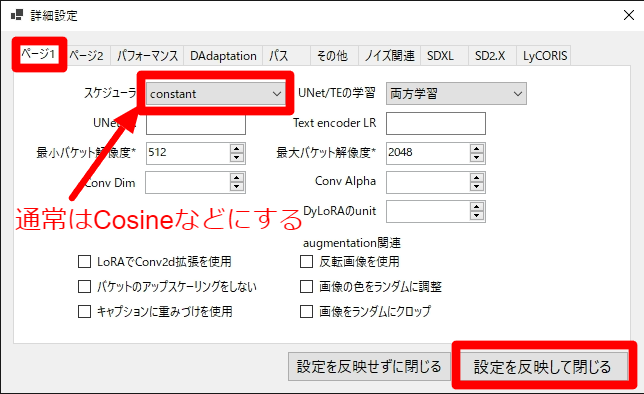
正直これだけでもお腹いっぱい感はあるのですが、この中だけでも調整項目はいくつもあり、学習率(LR)、epochs/steps、オプティマイザ、ネットワーク次元数、ネットワークアルファ、バッチサイズ、スケジューラについては、学習の目的や学習元モデル、学習の進みの良し悪しなどにより細かく調整する必要があります。
注)上で設定したパラメータは一般的なものではなく、特に学習率(LR)は意図的に高い値を指定しています。
3. 学習開始!
すべて値を設定したらいよいよ学習開始です。LRの数字が大きすぎる旨が警告として表示されるのですが、意図的に高い値としている為にそのまま実行します。
コマンドプロンプトの画面が開いて、大量のメッセージが表示されます。 triton 関連でエラーが出ますが、このエラーは無視してOKです。上手く実行できると 学習の経過が表示されるようになります。
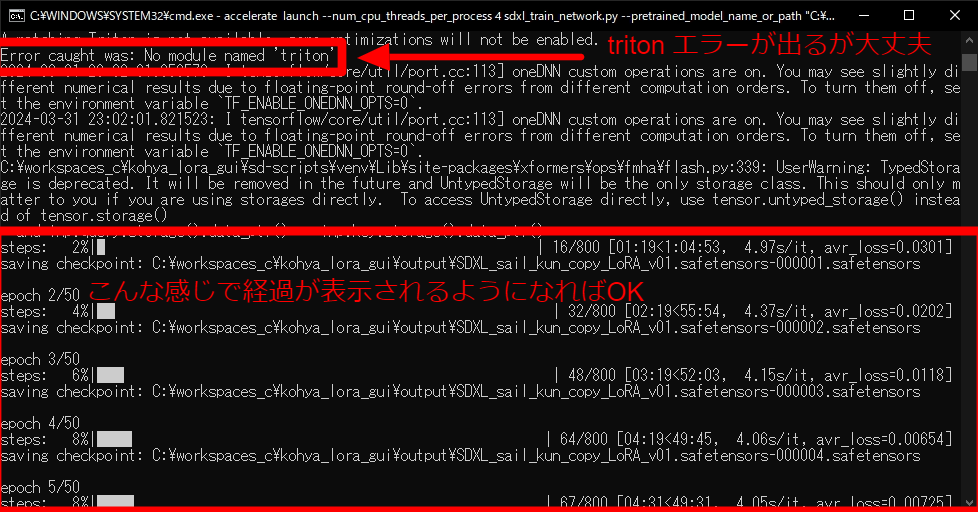
学習が開始するとGPUは全力で稼働を開始します。残り時間等をみると、どのくらいで規定ステップ数の学習が終わるのかの予想がつきます。この間、冬場でも部屋が熱くなるくらいの熱が出るので冷却には特に気を使ってあげてください。(高価なグラフィックボード壊れると泣けます…)
今回は一旦ここまで。
*1) AI 画像生成で利用するモデルというのは、AI画像生成を行う方式としてのアルゴリズムに相当する画像生成モデル(generative model)と、AI画像生成を行うために利用する学習データの入っている学習済みモデル(Pre-Trained Model)という言葉で表現されます。どちらも「モデル」で区別がつきにくいため、AI画像生成では学習済みモデルの方を checkpoint と呼んだりします。